Fehlerfortpflanzung#
Messverfahren#
In der Messtechnik gibt es zwei Möglichkeiten eines Messprinzips:
Das direkte Messverfahren: der gesuchte Messwert wird unmittelbar durch den Vergleich mit einem Bezugswert derselben Messgröße gewonnen. Als Beispiel eignet sich hier die Balkenwaage, die die unbekannte Masse \(m\) mit der bekannten Masse eines Gewichtssteins vergleicht.
Das indirekt Messerverfahren: Die meisten physikalischen Größen werden so ermittelt, da sie nur indirekt ermittelt werden können. Die gesuchte Messgröße wird hierbei über physikalische Zusammenhänge auf andere Größen zurückgeführt und anschließend aus diesen ermittelt. Die Federwaage ist ein Beispiel hierfür, bei der eine unbekannte Masse \(m\) über die Auslenkung \(x\) einer Feder (Federkonstante \(k\)) ermittelt werden soll. Gravitationskraft wird der Rückstellkraft der Feder gleichgesetzt und man erhält folgenden Zusammenhang, wobei \(g\) die Schwerebeschleunigung ist.

Durch dieses Beispiel wird klar, dass Messgrößen \(y\) oft nicht direkt ermittelt werden, sondern über funktionelle Zusammenhänge von \(n\) verschiedenen Messgrößen \(x_i\) bestimmt werden:
Achtung, bei \(x_i\) handelt es sich nicht um Stichprobengrößen \(x_j\), sondern um Messungen unterschiedlicher physikalischer Messgrößen, beispielsweise Federkonstante \(k\) und Auslenkung \(x\).
Die Messgrößen \(x_i\) werden häufig mehrmals gemessen. Wir wissen bereits, dass es bei so einer Messreihe immer leicht unterschiedliche Werte heraus kommen und wir diese mit Methoden aus der Statistik analysieren können. Wir wissen:
als Messergebnisse kann man die jeweiligen Mittelwerte \(\bar x_i\) einer Messreihe verwenden
als Messunsicherheit dient die Standardabweichung \(s(\bar x_i)\) der Mittelwerte, häufig erweitert mit Student-t-Faktor \(t\) oder \(k\) der Normalverteilung zur Messunsicherheit \(u(\bar x_1) = t \cdot s(\bar x_i) = t \cdot s(x_i)/\sqrt{m}\)
Um die gesucht Größe \(y\) zu erhalten, kann man nun mit den Mittelwerten \(\bar x_i\) weiterrechnen und zusätzlich die Unsicherheit, \(\Delta y\), angeben:
mit
Doch wie wirken sich Messunsicherheiten der Messgrößen \(x_i\) auf das Ergebnis \(y\) aus? Aus folgenden Diagramm ist ersichtlich, dass eine Abweichung der Größe \(x\) zwangsläufig eine Abweichung der Größe \(y\) zur Folge hat.
Show code cell source
#Benötigte Libraries:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import seaborn as sns
import time
import warnings
warnings.filterwarnings('ignore')
# MatplotLib Settings:
plt.style.use('default') # Matplotlib Style wählen
plt.figure(figsize=(6,4)) # Plot-Größe
plt.rcParams['font.size'] = 10; # Schriftgröße
link = 'data/graph.csv' # Beispieldatei mit Klimadaten
global_mean = pd.read_csv(link, header = 1) # Daten einlesen
global_mean["uncertainty"] = 0.25 #Messunsicherheiten abschätzen, hier 0.25K Temperaturgenauigkeit angenommen
x=global_mean.loc[global_mean["Year"] >= 1980,"Year"]
y=global_mean.loc[global_mean["Year"] >= 1980,"No_Smoothing"]
y_err = global_mean.loc[global_mean["Year"] >= 1980,"uncertainty"]
model = np.polyfit(x, y, deg=1, w=1/y_err, cov=True) # 1. Wert = Anstieg , 2. Wert = Schnittpunkt mit y-Achse
y_model = model[0][0]*global_mean["Year"]+model[0][1] # Modell einer linearen Regression
plt.plot(global_mean["Year"],global_mean["No_Smoothing"], ls="-", lw=1, marker="s", ms=3, color="tab:gray", alpha=0.5, label="Werte");
plt.plot(global_mean["Year"],y_model, ls="-", lw=1.5, color="tab:blue", label=f"lineare Regression y=({model[0][0]*1000:.3f}+-{np.sqrt(model[1][0][0]*1000):.3f})1e-3*x+({model[0][1]:.3f}+-{np.sqrt(model[1][1][1]):.3f})");
plt.xlabel('Größe x')
plt.ylabel("Größe y")
plt.annotate("",xy=(1980, 0.15), xycoords='data',xytext=(1980, -1), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "k", lw=3), )
plt.annotate("",xy=(1880, 0.15), xycoords='data',xytext=(1980, 0.15), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "k", lw=3), )
plt.annotate("",xy=(1960, -0.25), xycoords='data',xytext=(1960, -1), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=3, ls = '-.'), )
plt.annotate("",xy=(1880, -0.25), xycoords='data',xytext=(1960, -0.25), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=3, ls = '-.'), )
plt.annotate("",xy=(2000, 0.52), xycoords='data',xytext=(2000, -1), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=3, alpha = 0.5, ls = '--'), )
plt.annotate("",xy=(1880, 0.52), xycoords='data',xytext=(2000, 0.52), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=3, alpha = 0.5, ls = '--'), )
# X-Arrows:
plt.annotate("",xy=(1960, -0.75), xycoords='data',xytext=(1980, -0.75), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=2), )
plt.annotate('',xy=(2000, -0.75), xycoords='data',xytext=(1980, -0.75), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=2, alpha = 0.5), )
plt.annotate(r'$-\Delta x$',xy=(1960, -0.75),xytext=(1965, -0.7), color="tab:blue")
plt.annotate(r'$+\Delta x$',xy=(2000, -0.75),xytext=(1985, -0.7), color="tab:blue", alpha = 0.5)
# Y-Arrows:
plt.annotate("",xy=(1880, -0.25), xycoords='data',xytext=(1880, 0.15), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=2), )
plt.annotate('',xy=(1880, 0.52), xycoords='data',xytext=(1880, 0.15), textcoords='data',arrowprops=dict(arrowstyle="->",connectionstyle="arc3",color = "tab:blue", lw=2, alpha = 0.5), )
plt.annotate(r'$-\Delta y$',xy=(1881, -0.),xytext=(1881, -0.), color="tab:blue")
plt.annotate(r'$+\Delta y$',xy=(1881, 0.27),xytext=(1881, 0.27), color="tab:blue", alpha = 0.5)
plt.xlim([1880,2020])
plt.ylim([-1.0,1.1])
plt.grid();
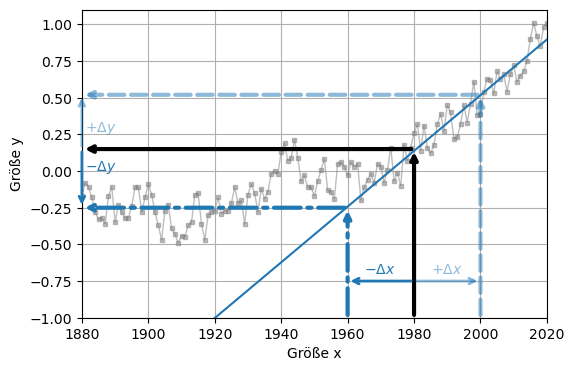
Das Intervall \(\pm \Delta x = 20\) im Diagramm um 1980 herum wird durch irgendeinen funktionellen Zusammenhang \(f(x)\) auf das Intervall \(\Delta y\) abgebildet. Durch den Messwert \(x_0 = 1980\) kann eine lineare Ausgleichsgerade gezogen werden, deren Steigung der Ableitung der Funktion in diesem Punkt entspricht, \(df(x_0)/dx\). Anhand der Steigung der linearen Ausgleichsgeraden kann man den Fehler für \(y\) direkt ablesen: \(\Delta y \approx 0,375\). Man sieht jedoch in der Abbildung auch, dass diese Abschätzung umso schlechter wird, je größer \(\Delta x\) ist. Je nach Funktionstyp müssen also auch höhere Ableitungen berücksichtigt werden (Taylorentwicklung von \(f(x)\)).
Herleitung (Taylor)#
Für eine allgemeine Funktion \(f(x) = y(x)\) einer Zufallsgröße \(x\) lässt sich die Frage nach der Unsicherheit näherungsweise beantworten, wenn man die Taylor-Entwicklung von \(y\) an der Stelle \(\bar x\) um deren Messabweichung \(\Delta x\) herum entwickelt:
Da die Unsicherheit typischerweise eine kleine Größe ist, wird die Reihenentwicklung nach dem linearen Glied abgebrochen, da höhere Ordnung von \((\Delta x)^2\) recht klein werden. Damit ergibt sich die Näherung:
Diese Formel gilt, wenn das Messergebnis von einer einzelnen Zufallsgröße abhängt. Kommen weitere Messgrößen dazu, welche voneinander unabhängig sind, wird die entsprechende Reihenentwicklung verwendet, welche ebenfalls bis zum linearen Glied als Näherung für kleine \(\Delta x\) angenommen werden kann:
wobei hier der Term \(\frac{\partial y}{\partial x_1}\) die partielle Ableitung der Funktion \(y(x_1, x_2, ...)\) nach der Größe \(x_1\) bedeutet. Wird die partielle Ableitung nach \(x_1\) berechnet, verhalten sich alle anderen Eingangsgrößen (\(x_2, ...\)) wie eine Konstante.
Warnung
Die nachfolgenden Gesetze sind nur bei hinreichender Linearität anwendbar, d.h. wenn sich die Funktion \(y(x_1, x_2, ...)\) bei Änderung einer der Eingsangsgrößen \(x_i\) im Bereich ihrer eigenen Unsicherheit \(u_i\) nur hinreichend linear verändert. Andernfalls wird die Fehlerfortpflanzung aufwendiger (DIN1319).```
Lineare Fehlerfortpflanzung#
Warnung
Diese Methoden werden nur für systematische Fehler angewendet.
Bekanntes Vorzeichen#
Ist das Vorzeichen der Messabweichung bekannt, müssen die Vorzeichen unbedingt berücksichtigt werden. Das Ergebnis wird anschließend um diesen Offset korrigiert und nicht mit dem \(\pm\)-Symbol, wie für Messunsicherheiten üblich versehen.
Die allgemeine Formel aus dem vorangegangenen Kapitel ist gültig und die Messabweichung für \(y\) berechnet sich zu:
Wichtige Spezialfälle sind Summen, Differenzen, Produkte oder Quotienten von zwei Größen. Beachte hier, dass wir in diesem Kapitel Fehler mit Vorzeichen betrachten, das heißt wir wissen, in welche Richtung der Messwert abweicht.
Spezialfälle
Die Spezialfälle vereinfachen sich aufgrund der Beträge zu folgenden Sachverhalten:
Setzt sich die gesuchte Größe \(y\) aus der Addition zweier unabhängigen Messwerte zusammen, so wird ihre Abweichung aus der Addition der Abweichungen der Einzelmessungen berechnet:
Setzt sich die gesuchte Größe \(y\) aus der Subtraktion zweier unabhängigen Messwerte zusammen, so wird ihre Abweichung aus der Subtraktion der Abweichungen der Einzelmessungen berechnet:
Setzt sich die gesuchte Größe \(y\) aus der Multiplikation zweier unabhängigen Messwerte zusammen, so wird ihre relative Abweichung aus der Addition der relativen Abweichungen der Einzelmessungen berechnet:
Setzt sich die gesuchte Größe \(y\) aus der Division zweier unabhängigen Messwerte zusammen, so wird ihre relative Abweichung aus der Subtraktion der relativen Abweichungen der Einzelmessungen berechnet:
Hierbei werden keine Fehlergrenzen (mit \(\pm\)) angegeben, sondern systematische Messabweichungen mit bekanntem Vorzeichen. Bei Fehlergrenzen und statischen Unsicherheiten, gelten andere Sacherverhalte (siehe nächsten Abschnitt)! Die Formeln gelten nur, wenn das Vorzeichen des Fehlers bekannt ist. Bei dieser Fehlerfortpflanzung können sich also Abweichungen ergänzen oder sogar aufheben, wie das folgende Beispiel zeigt.
Beispiel
Eine Messgröße \(x_1\) wird um 2% zu klein gemessen und Messgröße \(x_2\) um 3% zu groß.
Bei der Multiplikation \(y=x_1 \cdot x_2\) wird \(y\) um 5% zu groß gemessen (2% + 3% = 5%).
Bei der Division \(y=x_1 / x_2\) wird \(y\) um 1% zu klein gemessen (2% - 3% = -1%).
Unbekanntes Vorzeichen (Maximalfehler) #
Die Größe der Messabweichung eines Messgereätes ist zwar betragsmäßig bekannt, das Vorzeichen jedoch nicht. Somit sind nur die Grenzen dieser Abweichung bekannt. Die gesuchte Abweichung \(\Delta y\) der Messgröße \(y\) kann aber über denselben mathematischen Ansatz wie eben ermittelt werden, wobei wir annehmen, dass sich die Abweichungen im schlimmsten Fall bei ungünstigen Vorzeichenkombinationen zu einem Maximalfehler addieren:
Warnung
Auch wenn unbekannte Vorzeichen ebenfalls bei zufälligen Messunsicherheit auftreten, wird der Maximalfehler meist nur bei systematischen oder bei worst case Batrachtungen angewendet.
Spezialfälle
Die Spezialfälle vereinfachen sich aufgrund der Beträge zu folgenden Sachverhalten:
Setzt sich die gesuchte Größe \(y\) aus der Addition oder Subtraktion zweier unabhängigen Messwerte zusammen, so wird ihre Abweichung aus der Addition der Abweichungen der Einzelmessungen berechnet:
Setzt sich die gesuchte Größe \(y\) aus der Multiplikation oder Division zweier unabhängigen Messwerte zusammen, so wird ihre relative Abweichung aus der Addition der relativen Abweichungen der Einzelmessungen berechnet:
Gauß’sche Fehlerfortpflanzung #
Zufällige unabhängige Unsicherheiten#
Haben wir nun den Fall, dass sich die gesuchte Größe \(y\) aus mehreren voneinander unabhängigen Eingangsgrößen \(\bar x_1, \bar x_2, ...\) und deren Unsicherheiten \(u_1, u_2, ...\) zusammensetzt, werden jetzt, wie bei der Berechnung der Standardunsicherheit, die quadrierten Beiträge der Einzelunsicherheiten addiert werden:
Dies nennt sich auch das Gauß’sche Fehlerfortpflanzungsgesetz und wird bei Unsicherheiten, aber nicht bei systematischen Messabweichungen / Fehlern verwendet.
Spezialfälle
Die Spezialfälle vereinfachen sich aufgrund der Beträge zu folgenden Sachverhalten:
Setzt sich die gesuchte Größe \(y\) aus der Addition oder Subtraktion zweier unabhängigen Messwerte zusammen, so wird ihre quadrierte Unsicherheit aus der Addition der quadrierten Unsicherheiten der Einzelmessungen berechnet:
Setzt sich die gesuchte Größe \(y\) aus der Multiplikation oder Division zweier unabhängigen Messwerte zusammen, so wird ihre relative quadrierte Unsicherheit aus der Addition der relativen quadrierten Unsicherheiten der Einzelmessungen berechnet:
Beispiel aus dem Video
Es soll der elektrische Widerstand eines \(l = 100\,\mathrm m\)-langen Spulendrahtes mittels Messungen ermittelt werden:
wobei \(\rho\) der spezifische Widerstand und \(d\) der Durchmesser des Drahtes sind. Beide Größen wurden mehrmals gemessen, wobei unterschiedliche Messwerte herausgekommen sind, aus denen Mittelwerte und Standardabweichungen berechnet worden sind:
Aus dem Mittelwerten wird die gesuchte Größe \(R\) berechnet:
Die Unsicherheit wird mittels Gauß berechnet:
Die Ableitungen sollte man vorher separat berechnen:
Und alle Formeln und Größen einsetzen:
Angabe des Endergebnisses:
Dies ist die allgemein übliche Herangehensweise. In diesem Fall hätte man aber auch eine Variante des Spezialfalls für Division anwenden können:
wobei hier bei dem Exponenten von \(d\) ein Faktor \(2\) berücksichtigt werden muss, da \(d^2\) (bzw. \(d^{-2}\)) in der Formal auftritt:
Aufgelöst nach \(\Delta R\) erhält man ebenfalls:
Show code cell content
import numpy as np
drho = 3e-8
rho=1.7e-6
dd = 3e-6
d=87e-5
l = 100
R = rho*4*l/(np.pi * d**2)
print('R = ', R)
# Allgemein:
dRdrho = 4*l/(np.pi*d**2)
dRdd = - rho*8*l/(np.pi*d**3)
dR_1 = np.sqrt((dRdrho * drho)**2 + (dRdd * dd)**2)
print('dR = ', dR_1)
# Divisions-Spezialfall:
rho_relative = drho/rho
d_relative = 2*dd/d
dRR2 = rho_relative**2 + d_relative**2
dR_2 = np.sqrt(dRR2 * R**2)
print('(dR/R)^2 = ', dRR2)
print('dR = ', dR_2)
R = 285.97003911345973
dR = 5.418216235738347
(dR/R)^2 = 0.0003589811108048171
dR = 5.418216235738347
Zufällige abhängige Variablen #
Häufig liegt in der Messtechnik der Fall vor, dass wir voneinander unabhängige Messungen betrachten und diese zu unserer gesuchten Messgröße kombinieren. Teilweise können aber auch Messungen beobachtet werden, welche eine Abhängigkeit voneinander aufweisen. In diesem Fall spricht man von Korrelationen zwischen Messgrößen und ein Kovarianz-Term muss berücksichtigt werden!
Korrelation#
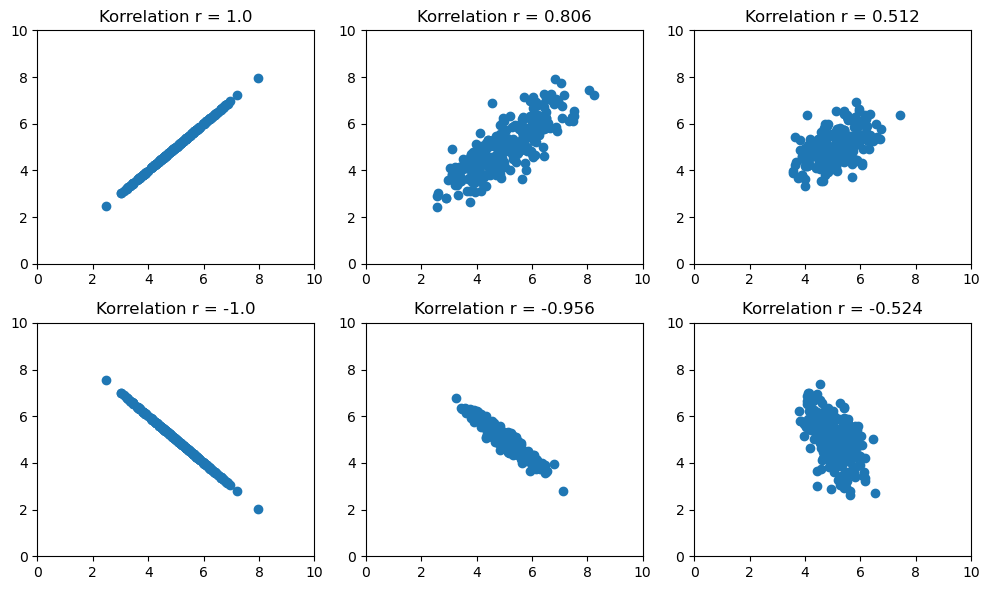
Der Korrelationskoeffizient \(r\) kann nur Werte zwischen +1 und -1 annehmen, wobei +1 einen perfekten positiven Zusammenhang und -1 einen perfekten negativen Zusammenhang beschreiben. Ist \(r = 0\), so gibt es keinen Zusammenhang zwischen den betrachteten Variablen, sie sind also unabhängig voneinander.
Warnung
Der Korrelationskoeffizient \(r\) erkennt nur lineare Zusammenhänge. Sind zwei Variablen unkorreliert, kann immer noch ein nicht-linearer Zusammenhang, z.B. exponentiell oder quadratisch, zwischen ihnen bestehen.
Show code cell source
def scatterplot(x, y):
rho = np.corrcoef(m_1,m_2)[1,0]
plt.scatter(x, y, color="tab:blue")
plt.title('Korrelation r = ' + str(round(rho,3)))
plt.xlim([0,10])
plt.ylim([0,10])
plt.figure(figsize=(10,6)) # Plot-Größe
# MatplotLib Settings:
plt.style.use('default') # Matplotlib Style wählen
#plt.xkcd()
plt.rcParams['font.size'] = 10; # Schriftgröße
# Zufallszahlen erzeugen
u_1 = np.random.randn(250)
u_2 = np.random.randn(250)
u_g = np.random.randn(250)
# richtige Werte
r_1 = 5.0
r_2 = 5.0
# Plot 1:
# einzelne und gemeinsame Unsicherheit
s_1, s_2, s_g = 0.0, 0.0, 1.0
# Simulierte Messwerte erstellen
m_1 = r_1 + s_1*u_1 + s_g*u_g
m_2 = r_2 + s_2*u_2 + s_g*u_g
plt.subplot(2,3,1)
scatterplot(m_1, m_2)
# Plot 2:
# einzelne und gemeinsame Unsicherheit
s_1, s_2, s_g = 0.5, 0.5, 1.0
# Simulierte Messwerte erstellen
m_1 = r_1 + s_1*u_1 + s_g*u_g
m_2 = r_2 + s_2*u_2 + s_g*u_g
plt.subplot(2,3,2)
scatterplot(m_1, m_2)
# Plot 3:
# einzelne und gemeinsame Unsicherheit
s_1, s_2, s_g = 0.5, 0.5, 0.5
# Simulierte Messwerte erstellen
m_1 = r_1 + s_1*u_1 + s_g*u_g
m_2 = r_2 + s_2*u_2 + s_g*u_g
plt.subplot(2,3,3)
scatterplot(m_1, m_2)
# Plot 4:
# einzelne und gemeinsame Unsicherheit
s_1, s_2, s_g = 0.0, 0.0, 1.0
# Simulierte Messwerte erstellen
m_1 = r_1 + s_1*u_1 + s_g*u_g
m_2 = r_2 + s_2*u_2 - s_g*u_g
plt.subplot(2,3,4)
scatterplot(m_1, m_2)
# Plot 5:
# einzelne und gemeinsame Unsicherheit
s_1, s_2, s_g = 0.2, 0.1, .7
# Simulierte Messwerte erstellen
m_1 = r_1 + s_1*u_1 + s_g*u_g
m_2 = r_2 + s_2*u_2 - s_g*u_g
plt.subplot(2,3,5)
scatterplot(m_1, m_2)
# Plot 6:
# einzelne und gemeinsame Unsicherheit
s_1, s_2, s_g = 0.2, 0.8, 0.5
# Simulierte Messwerte erstellen
m_1 = r_1 + s_1*u_1 + s_g*u_g
m_2 = r_2 + s_2*u_2 - s_g*u_g
plt.subplot(2,3,6)
scatterplot(m_1, m_2)
plt.tight_layout()
plt.show()
Die Berechnung des Korrelationskoeffizienten zwischen zwei Variablen, \(x_1\) und \(x_2\), kann auf zwei verschiedene Arten erfolgen:
Kovarianz#
Eine alternative Berechnung des Koeffizienten ergibt sich aus der sogenannten Kovarianz-Matrix, die durch die jeweiligen Standardabweichungen der beiden Variablen normiert wird:
Für mehr als zwei Variablen ergibt sich eine komplexe Matrix:
die alle möglichen 2er-Kombinationen zwischen den verschiedenen Variablen enthält.
Bei unabhängigen Messungen ist die Kovarianz null:
In korrelierten Messungen treten gemeinsame Unsicherheiten auf, insbesondere wenn alle Messungen eine gemeinsame systematische Unsicherheit haben:
Diese gemeinsame Unsicherheit führt dazu, dass Abhängigkeiten zwischen den gemessenen Werten \(x_1\) und \(x_2\) auftreten. Zum Beispiel, wenn \(x_1\) zu groß ist, erhöht sich die Wahrscheinlichkeit, dass auch \(x_2\) zu groß ist, was als positive Korrelation bezeichnet wird. Umgekehrt würde eine negative Korrelation bedeuten, dass ein zu großer Wert von \(x_1\) wahrscheinlicher ist, wenn \(x_2\) zu klein ist.
Unabhängige Variablen haben keinen Einfluss aufeinander, und in diesem Fall ist die Korrelation genau null.
Warnung
Es ist wichtig zu beachten, dass die Kovarianz von der Skalierung abhängt und daher weniger geeignet ist, um Größen zu vergleichen. Der Korrelationskoeffizient ist hingegen normiert und dient als Maß für Korrelationen, insbesondere für lineare Korrelationen. Es ist jedoch Vorsicht geboten, da ein hoher Korrelationskoeffizient nicht unbedingt auf eine starke Korrelation hinweist, da Ausreißerwerte den Wert beeinflussen können.
Das Gauß’sche Fehlerfortpflanzungsgesetz muss nun erweitert werden, um die Kovarianzen oder die Korrelationskoeffizienten zwischen jeweils zwei Größen für alle \(n\) Messgrößen zu berücksichtigen.
Wenn eine Messgröße \(y\) aus \(n\) fehlerbehafteten Größen \(x_1 \pm u_1, x_2 \pm u_2, \ldots, x_n \pm u_n\) zusammengesetzt ist (die Mittelwertschreibweise \(\bar x_i\) wurde hier der Übersichtlichkeit halber weggelassen), gilt für ihre Unsicherheit:
Spezialfälle
Die Spezialfälle vereinfachen sich aufgrund der Beträge zu folgenden Sachverhalten:
Addition und Subtraktion zweier korrelierter Messwerte führt zu folgendem Fehlerfortpflanzungsgesetz:
Multiplikation oder Division zweier korrelierter Messwerte führt zu folgendem Fehlerfortpflanzungsgesetz:
der spezielle Fall für \(y = f(x_1, x_2, ... x_n)\) und 100% abhängige (100% korrelierte) Variablen:
Differentialle Datenübertragung#
Dieses Beispiel findet häufig Anwendung im Bereich der Signalübertragung und ist unter der Bezeichnung differentielle Signalübertragung bekannt. Neben dem eigentlichen Signal, \(x_1\) wird hierbei ein zweites, invertiertes Signal mitübertragen, \(x_2 = -x_1\). Da alle Störungen innerhalb der gleichen Übertragungsstrecke fast vollständig korreliert sind, heben sich diese am Ende auf. Das Nutzsignal erhält man zurück, indem man folgende Signalkombination berechnet: \(y = 0{,}5\cdot (x_1 - x_2)\). Aufgrund des hohen Korrelationsgrades der einzelnen Signalkomponenten ist die Unsicherheit des extrahierten Signal sehr klein: \(u_y \simeq 0\).
Vollständige Herleitung
Mittels Gauß’scher Fehlerfortpflanzung lässt sich die Messunsicherheit für
wie folgt allgemein bestimmen:
Die Sensitivitätskoeffizienten sind:
Eingesetzt in die obige Gleichung folgt:
Mit dem Korrelationskoeffizienten
lässt sich die Kovarianz durch \(r\) ausdrücken:
Im Spezialfall identischer Unsicherheiten \(u_1 = u_2 = u\) folgt:
Das Ergebnis für \(r = 0\), d.h. unabhängige Messwerte, der kombinierten Messunsicherheit für \(y\) beträgt \(u_y = u/\sqrt{2} = 0{,}35\)
Das Ergebnis für \(r = 1\), d.h. korrelierte Messwerte, der kombinierten Messunsicherheit für \(y\) beträgt \(u_y = 0{,}0\)